Grokking Lied to Me.

Since the original mechanistic interpretability research, I found a big chasm in my understanding between "this neuron fires every time Trump is in the input" and 6D hyper-structures that correspond to understanding line breaks. With so much to learn in the transformer space, I parked mechanistic interpretability for a while and decided to go to some first principles - like transformer fundamentals (my Git repo). However, Welch Labs recently posted a YouTube video on Grokking, which immediately piqued my interest.
Grokking is basically what it sounds like. It's the difference between memorizing notes to play a specific song and understanding specific chord progressions sound good. In Bloom's Taxonomy, it's like knowledge versus comprehension. More specifically in machine learning, it's the idea that after training set performance has converged, we can keep running training – for hundreds of epochs – and then then later an emergent capability happens where suddenly we go from memorization to generalization. The specific example used is modular arithmetic (a + b) mod n.
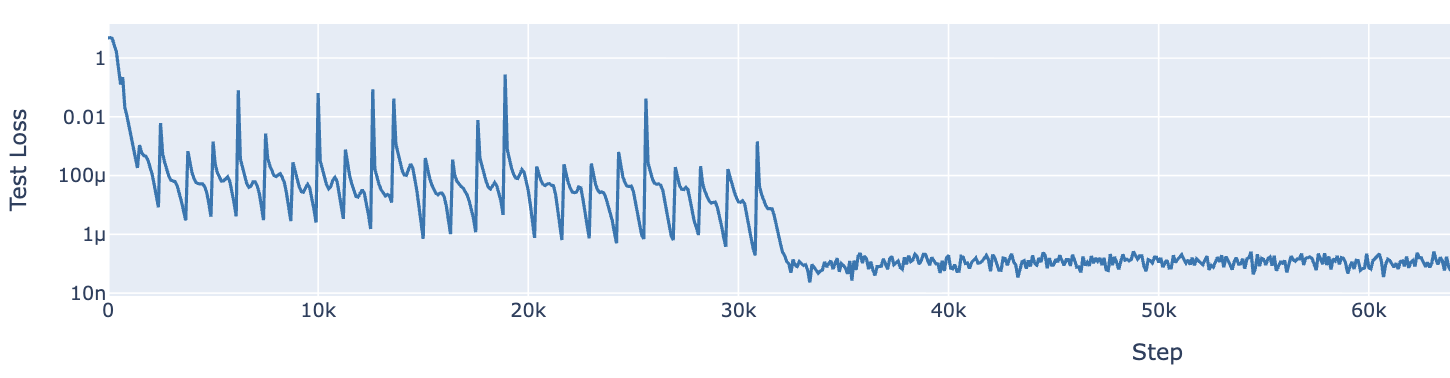
Super interesting, right? That means even though our loss looks pretty good, our training accuracy looks good, something is still happening. When you start peel back the onion, familiar shapes start appearing - namely trig functions. I suppose I remember more of my electrical engineering degree than I thought, because this felt intuitive and immediately make me think about Fourier transforms – frequency domain approximations of functions. Is the network doing math in the frequency domain to compute modular arithmetic?
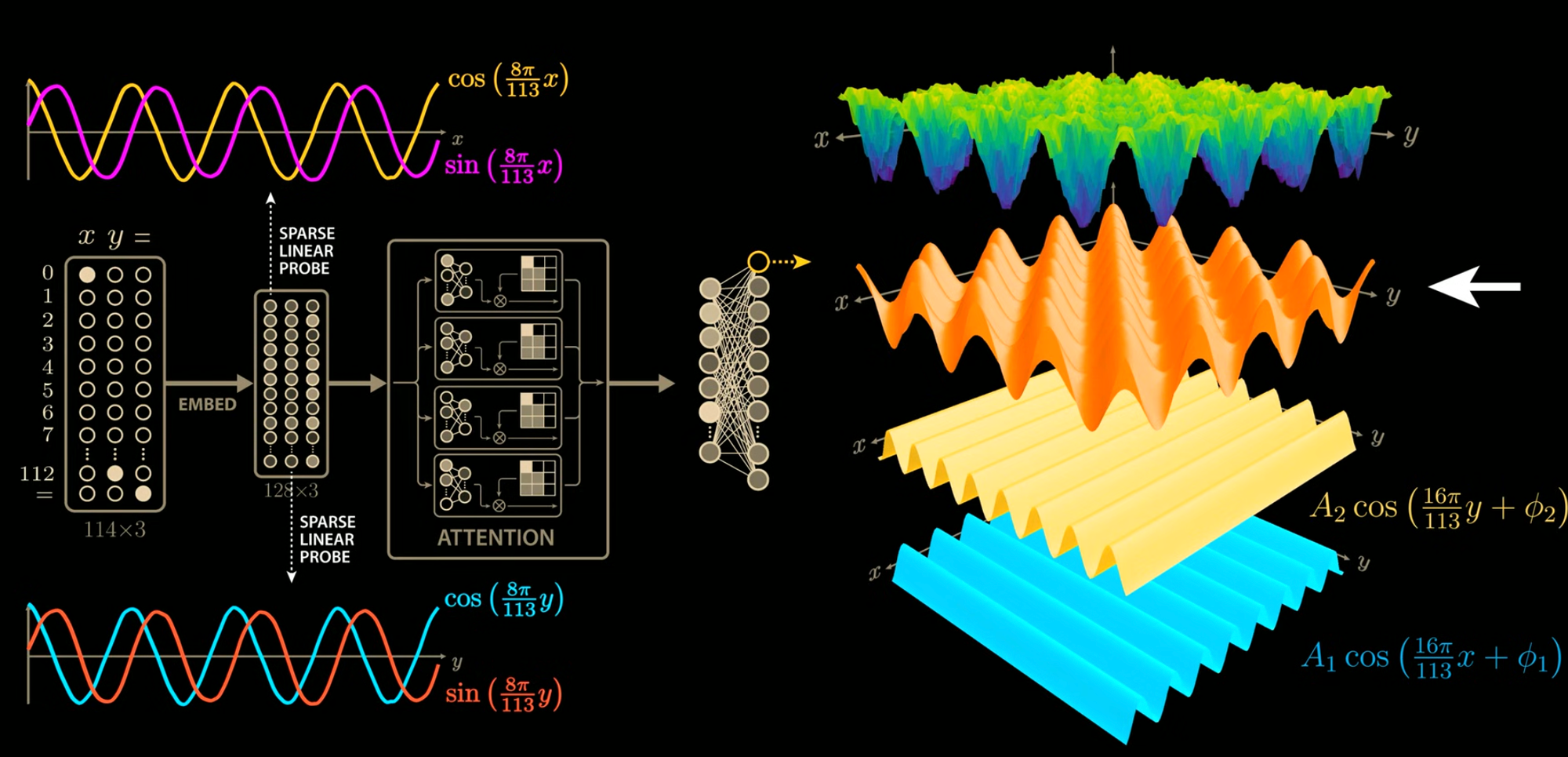
Seeing is believing, and this video had my mind racing. While playing board games with family over Christmas, all my mind could think about what this. Was Grokking just smoothing out the network's functions? How can we Grok faster? How do we regularize and measure curvature? Generalizing is like lower-order functions... how can we analyze the complexity? Lower-order Fourier approximations? Ideas ideas...
Without dedicated focus blocks, I found myself in scattered conversations with Claude discussing all the possibilities. Coming up with a plan, refining it, poking around different mathematical formulations I haven't used in ages. The thing is - LLMs basically incorporate everything I love – from calculus to shape back propagation to philosophical quandaries how an AI should behave, to the very process of learning itself. Perhaps here I could do something interesting - and at a small enough scale to iterate quickly! Can we take a moment to appreciate the irony of using hundreds of thousands of parameters to compute modular arithmetic?
I took the previous plan and iterated with Claude chats and Claude code for hours to formulate a plan to see how to test some theories to "Grok" faster. I kicked off my first Grokking experiment. Hmm, no test convergence. Is the a bug? Let's tune weight Decay. Learning rate. Let it run longer. Bigger network? How about switching to a Transformer? Reuse my previous implementation, nice! Convergence? Uhh... Kinda? Apparently this stuff was really sensitive to hyper-parameters. Fair enough. Let's set up a sweep, run it over night, come back in the morning. The results...?
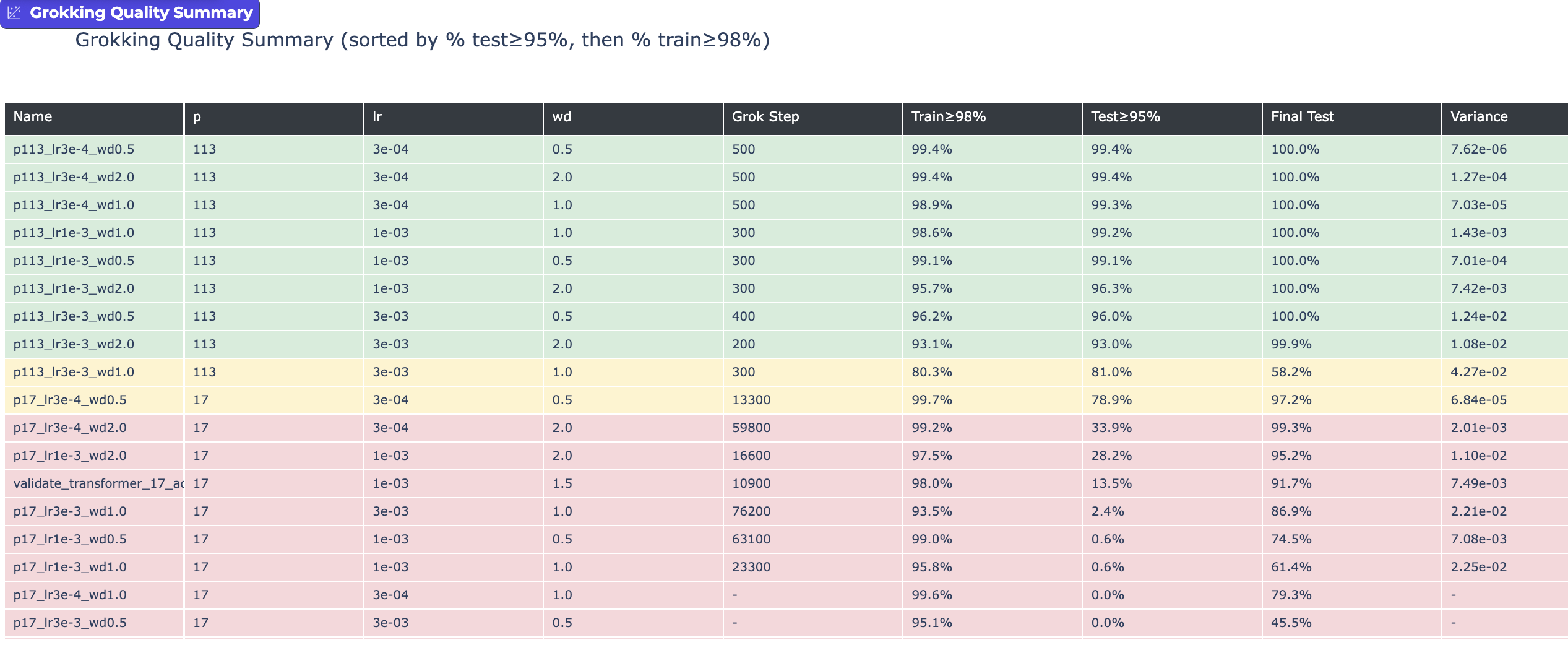
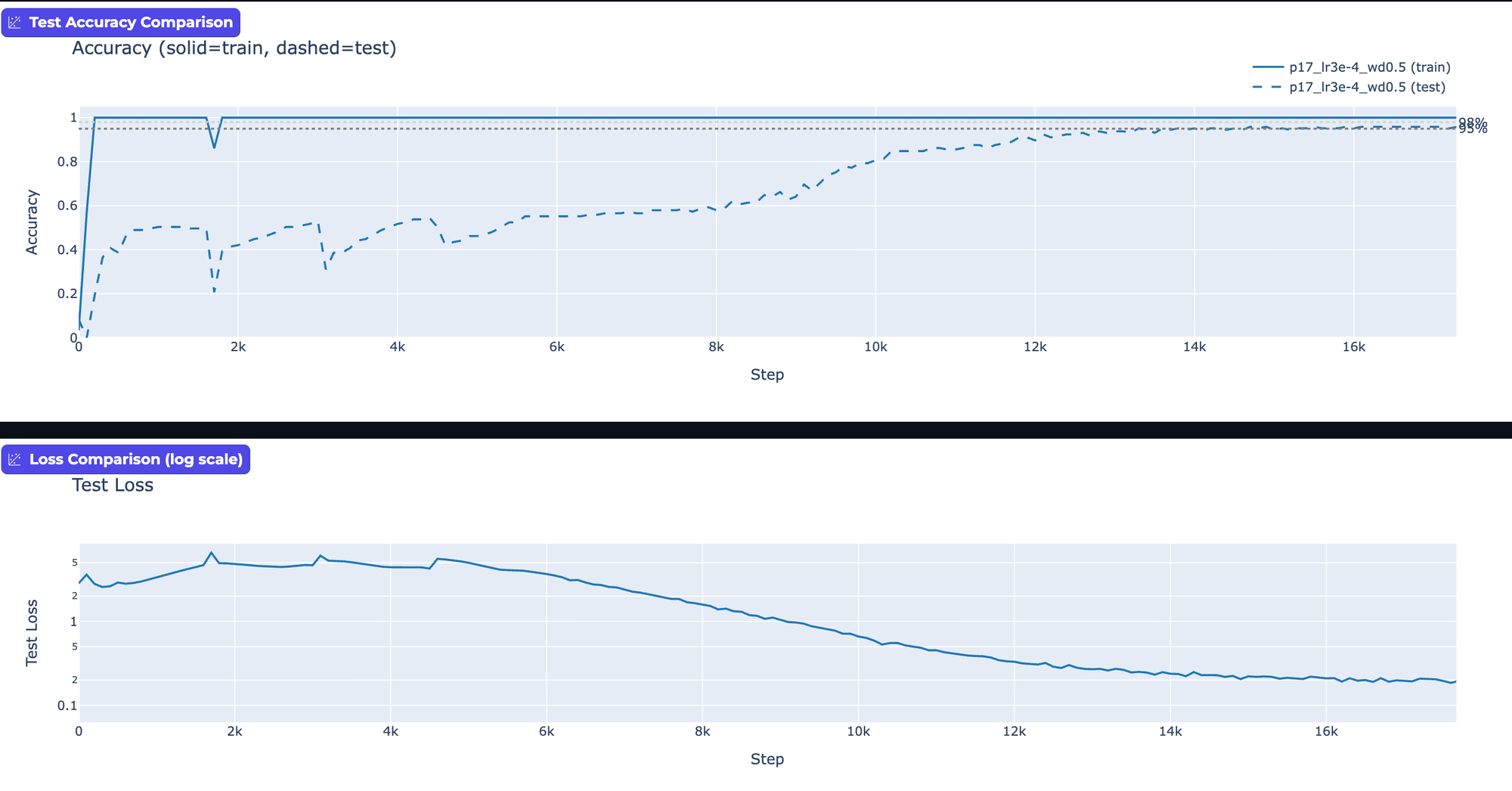
The morning often brings clarity, and alas it has again. Seriously, look at the results. Okay, I'll walk you through them - there isn't actually that much going on. We've got a transformer network trying to learn the modular arithmetic function for p=17 and p=113, and we're varying learning rates and weight decay. And the results are... wildly different.
Take a look again at the first "Grokking" graph versus the one directly below. Same modular arithmetic. Same transformer network. Same training process. Yet we "Grokked" mod 113 in ~500 steps, but Grokked mod 17 in 13,300? What? With the same learning rate, weight decay, and network configuration, the simpler mod function (p=17) took >20x longer to "Grok".
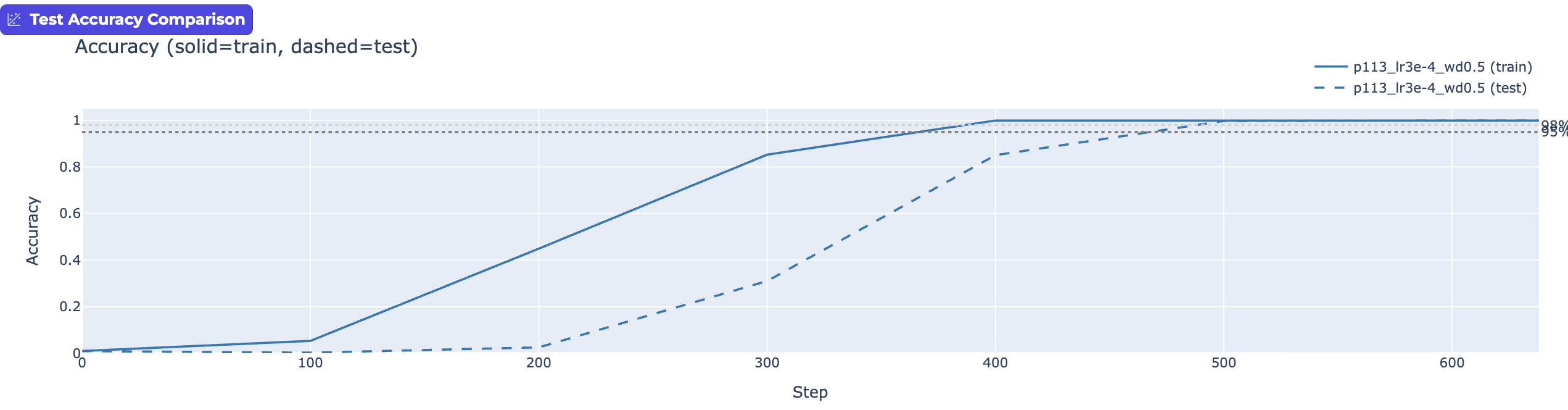
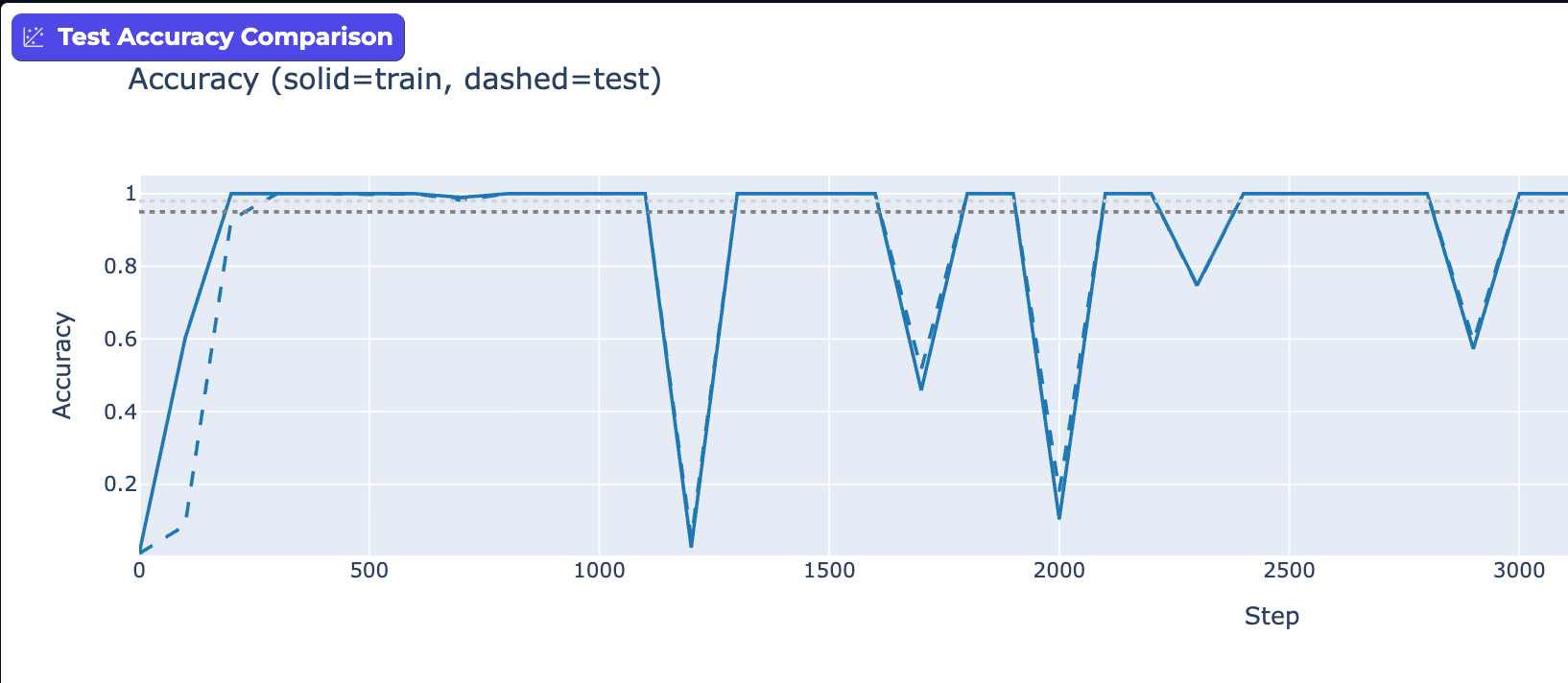
My experiments showed that Grokking can happen just a few hundred epochs in, where test accuracy just barely lags behind training. Or, it can happen 10s of thousands of steps in. Just by playing with learning rates and weight decay. For me this makes a strong case that when [at least] these two parameters are in balance, we've tuned the network to oscillate between memorization and generalization.
One way to look at this is try to understand how the network is responding. Is it hyper-sensitive to changes in inputs? Think "steep slope". Or is it doing a good job generalizing? Think "smooth curves". To understand this, we can measure how sensitive the network is (Jacobian) and whether its loss landscape is smooth or jagged (Hessian). A jagged landscape causes oscillation; a smooth one allows steady learning. We can see the network trying to make progress to smooth out the inner functions, but then fall back. Once we break out of the oscillation, we test accuracy steadily improves.
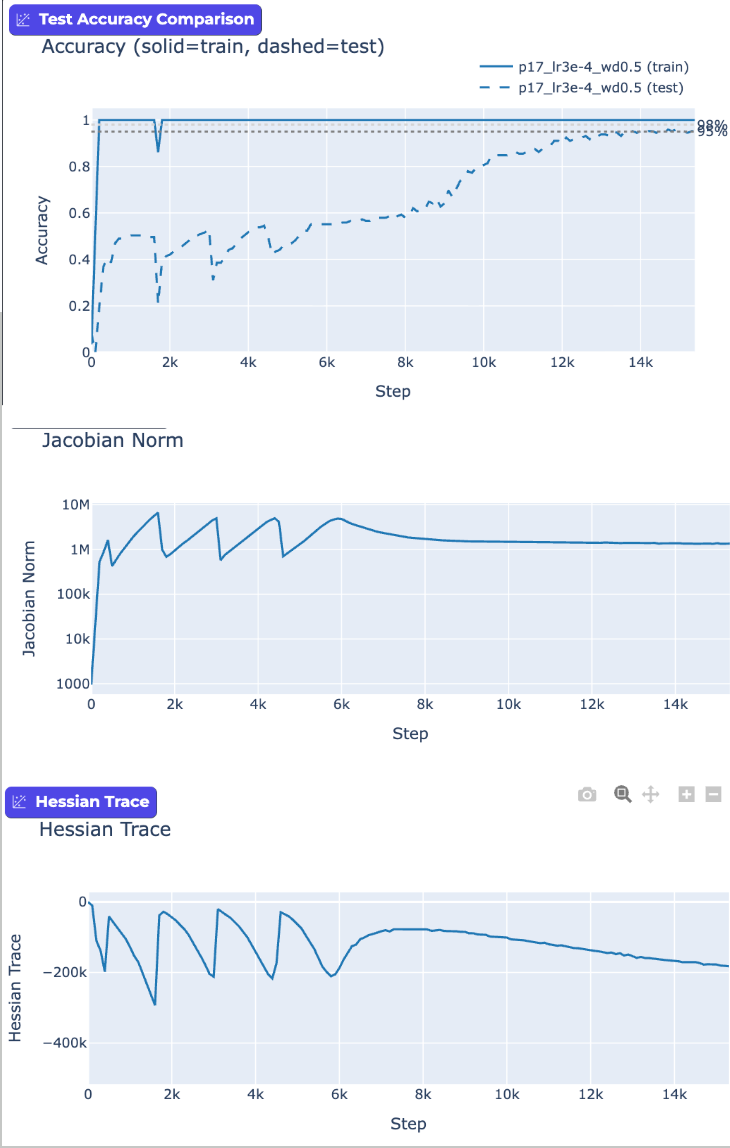
In fact, this suggests that the "Grokking" is phenomenon introduced by specific hyper-parameters, rather than an intrinsic property of the training neural nets! Specific tuning choices trigger oscillation, and aren't even necessarily the norm.
So while my excitement to accelerate learning is very much alive, Grokking "lied to me" by presenting itself as this beautiful test bed to validate the speed of generalized learning, when in fact it's an artifact of specific experimental setup.


