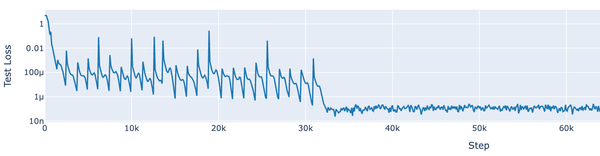
You Can’t Automate Understanding Your Problem.

Happy New Year! How was your break? What did you do? Vibe coded? An agent you say–what does it do? Ah interesting!
If you work in tech right now, there’s quite a few of these conversations floating around the office. We’ve all been seduced by the allure of vibe coding and how easy it is to create things. And as builders and tinkerers, “engineers” if you will, we’ve decided now was the time to take matters into our own hands. To build that killer app idea prototype. To make a game for fun. To automate that annoying workflow we deal with manually.
As we drift back into work mode, we carry the same enthusiasm. If agents can be used to solve these niche problems in our personal lives, what can they do at scale? How can they automate our problems in production? Solve our data utilization issues? Accelerate our deployment process? Optimize our ML features and improve model efficiency? We saw first hand the efficacy of agents, now, we just need to scale them up!
First we experiment with prompts, what do we need to tell this agent to do? Then we might go into tool development - well actually, this agent needs to be able to query certain databases or fetch and run code. Now it’s getting interesting, but there’s so much context to manage for this complex task… how do we organize the knowledge? Knowledge graphs? RAG? Memory? What does our tech stack provide, what can we wire up, and what do we need to will into existence?
The software engineering kicks in hard here: this is clearly an infrastructure problem now. We’ve got 200K tokens to work with and a problem that’s occupied multiple engineers for months. How do we build the right progressive disclosure? How do we partition the problem? What sub-agents and sub-tasks do we need to record? Time to pull up Claude (or GPT, or Copilot…) and start iterating with it on the ideas. Provide it some web links, some code pointers, some … wait a second.
How is this LLM I’m interacting with able to build my evaluation benchmark and provide an “expected output” definition that looks very reasonable. Is this… general purpose model able to do what my agent is trying to do? Wait, this chat interface isn’t just a base LLM anymore – it’s an agent. It has access to web search, the ability to write code and run it in its own environment. It even has its own working memory of past conversations! ...What exactly was special about that agent I’m building?
Put the brakes on the hype train for a moment. Let’s be a bit more analytical for a moment, and take a look at the AI landscape:
Layer 1: The base LLM
- Only the frontier models are valuable in the majority of scenarios
- Doesn’t just “know things”, but can actually reason about problems
- Constantly improving, including the ability to reason, plan, and operate tools
Layer 2: The Agentic Applications
- A few curated agents dominate the market, think “Claude code”
- Allows the model access beyond the context - domain knowledge, tools, skills, etc.
- Curation is king: while there are tons of tools and skills, a few really good ones dominate (e.g. web search, code execution)
Layer 3: The Problems we need solved
- Productivity gains remain uneven—some workflows transformed, others barely touched
- Evaluation is maturing but incomplete (benchmarks, LLM-as-judge, human review)
- The real measure: did it actually solve the problem you needed solved?
Right now, we seem to be in a state of a “fat middle” - lots of engineers building agentic applications. We’re investing in new agents, orchestration of agents, context and memory management for agents, consolidating knowledge for agents. Basically, anything we can do to make the base LLM more effective. All of this feels really intuitive as a software engineer, because the premise of our job is architecting solutions by wiring together pieces in novel ways. We see a new data processor (the AI), and are eager to wire up that processor with all the means necessary for it to succeed.
But let’s step back to the last point about the efficacy of that general purpose AI somehow able to solve your very specific problem that you were building an agent to solve. Yet, at the same time – it can’t really solve completely, or at scale. It can help you sketch out specific examples that you might use as an evaluation benchmark, but it’s not actually enabling you to automate at scale the way you might have initially thought. Why?
I want to introduce you to a term I (humbly admit) only recently really understood: ontology
- On·tol·o·gy - a particular theory about the nature of being or the kinds of things that have existence
Okay, what? Stay with me! More specifically, “problem ontology” has a more useful definition - the “systematic categorization and structural framework used to classify different types of problems based on their fundamental characteristics”. Great, so why am I telling you this?
When we seek to automate a problem, we're actually trying to map out its ontology. This means two things.
First, defining the problem itself: What does success actually look like? What trade-offs are we implicitly making? If I say the problem is standardizing data schemas for X, and you say it's standardizing schemas for Y, how do those fit into the broader goal we're actually after? Most problems have hidden priorities and unstated constraints that live in people's heads — ontology work forces you to make them explicit.
Second, decomposing the problem into executable steps: What actions do we actually need to perform? What are the atomic units of work, and what can be parallelized? Where are the key decision points, and how do we recover when something fails? This is where vague goals become concrete enough that something — human or agent — can actually act on them.
To define and decompose a problem requires understanding it deeply. The reason it takes multiple people, multiple weeks, months, or years to solve problems is because they don’t even fully know what the ideal solution looks like, much less the path to get there. And when we try to fork our complexity over to an agent, we’re actually asking it – and ourselves – to figure out the ontology of the problem.
And about all that knowledge you're organizing for your agent. Are you really organizing all the knowledge in existence, or are you actually ensuring it exists at all? If it's the latter, you're not doing agent development. You're curating knowledge, and that's valuable on its own terms. The 'agentic' wrapper might just be the forcing function that finally made you write things down.
Finally, let me be more direct: the hype for agentic development (for most of us) is misdirection at best. The true intellectual labor is understanding your problem, not architecting the ideal agentic framework, tools, and knowledge for your use-case. Yes, you can "get ahead of the curve" by building custom agents and integrations because the current baseline can't yet execute your specific workflow. But let me remind you: 9 months ago, Claude couldn't search the internet. Now it can write and execute code, maintain memory across sessions, and apparently integrate with your browser and desktop. The infrastructure is converging. The ontology of your problem isn’t.